TOP
>
歌声の研究(ボイトレ研究)TOP
>フォルマントとは何か?
2017.3.14更新 2017.3.14作成
話す人は声(=空気の振動)を発し、聞き手は声(=空気の振動)を聞き取る
人が会話をするとき、声という名の空気振動をキャッチボールしています。
人それぞれ違った個性の声を持っていますが、なぜ、相手が話している「あ」「い」「う」「え」「お」を「あ」「い」「う」「え」「お」と認識できるのでしょうか?
相手の声の何を聞き取って「あ」「い」「う」「え」「お」と認識しているのでしょうか?
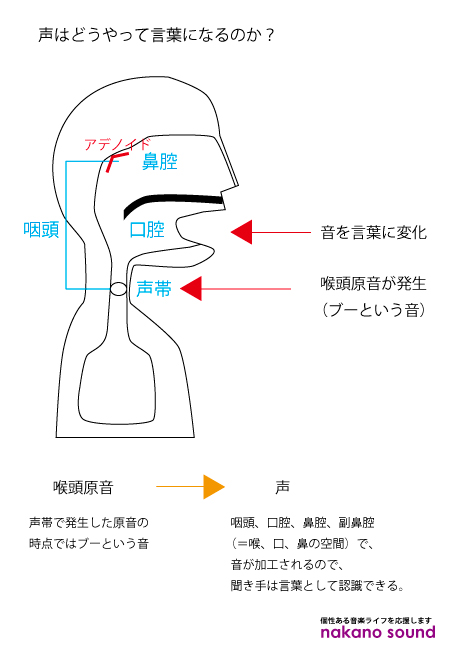
声が出るメカニズム(かなりザックリとした説明)
下図のようなメカニズムで、声が出ます。
声帯で原音が発生し、それを喉、口、鼻で加工する(=共鳴、増幅)ことにより、我々が普段耳にしている「声」となりま
す。
この「喉、口、鼻での加工」によって、
原音に「あ」「い」「う」「え」「お」の響きが付加
され、「声」となります。
声帯での原音(喉頭原音)は、話し声で 男性平均100~150Hz、女性平均250~300Hzとされています。 (本格的に統計を取ったわけではないと思うので、数値は目安としてください。)
フォルマントと「あ」「い」「う」「え」「お」の響き
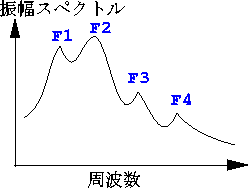
声帯で生じた原音が喉、口、鼻で加工されることにより、
音量が増幅されると同時に、倍音の特定の周波数において音量のピークができます。
(下図)
引用
http://media.sys.wakayama-u.ac.jp/kawahara-lab/LOCAL/diss/diss7/S3_6.htm
このピークのことをフォルマントと言います。
低い方から、第一フォルマント、第二フォルマント、第三フォルマント、第四フォルマントと呼ばれ、F1,F2,F3,F4と表されます。
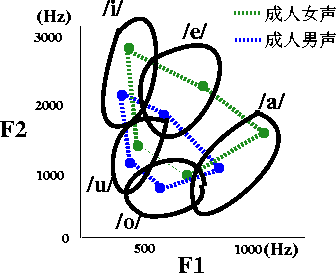
人間は、「あ」「い」「う」「え」「お」を、フォルマント(特に、F1とF2)によって認識しています。
「あ」を発するときのF1,F2、「い」を発するときのF1,F2、「う」を発するときのF1,F2、「え」を発するときのF1,F2、「お」を発するときのF1,F2、を聞き取ることによって、言葉を認識し、会話が成立しています。
F1とF2は下図のようにまとめられます。
引用
http://media.sys.wakayama-u.ac.jp/kawahara-lab/LOCAL/diss/diss7/S3_6.htm
また詳細は今後触れていきますが、例えば「あ」はF1が高く、F2が低い、「い」はF1が低く、F2が高いということが言える図になります。
上記のように
○声帯で発生した音が、喉、口、鼻で加工される
○加工されることによって、特定の周波数の音がピークとなる(=フォルマント)
○人間はフォルマントを聞き取ることによって、言葉を認識する
ということになります。
【このページの参考文献】
ヨハン スンドベリ 歌声の科学(2007)
和歌山大学大学院システム工学研究科聴覚メディア研究室HP http://media.sys.wakayama-u.ac.jp/kawahara-lab/LOCAL/diss/diss7/S3_6.htm